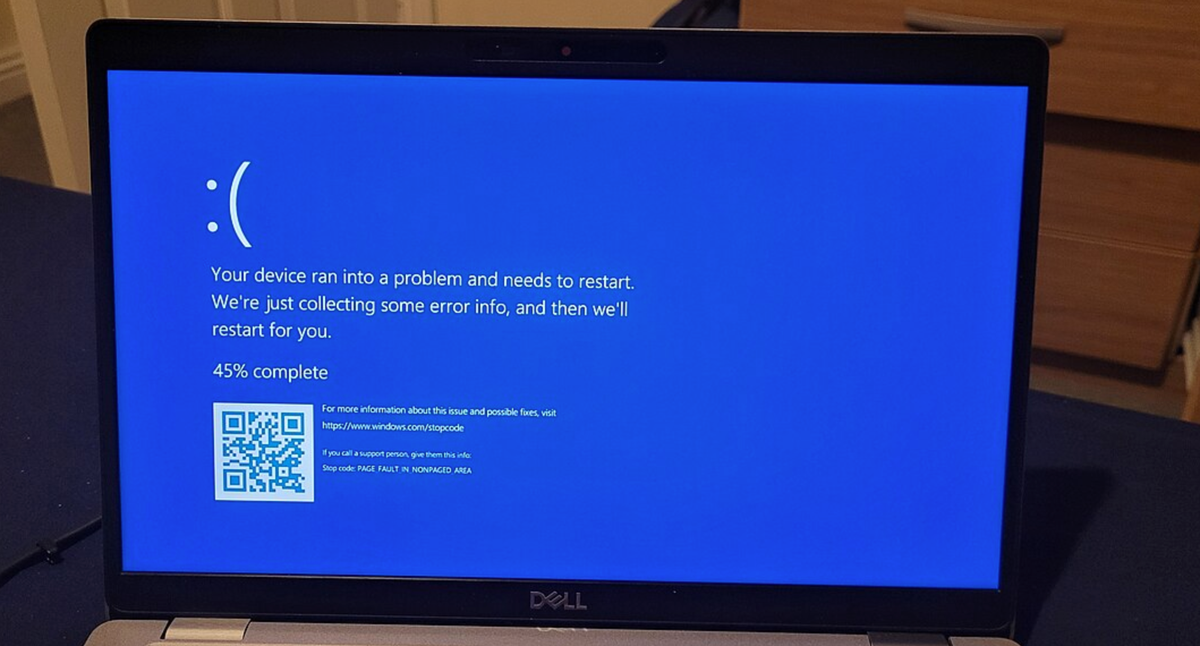
If this somehow works, good on Microsoft, but what the fuck are they doing on boot cycles 2-14? Can they be confined to do it in maybe 5? 3? Some computers have very long boot cycles.
There’s nothing magical about the 15th reboot - Crowdstrike runs an update check during the boot process, and depending on your setup and network speeds, it can often take multiple reboots for that update to get picked up and applied. If it fails to apply the update before the boot cycle hits the point that crashes, you just have to try again.
One thing that can help, if anyone reads this and is having this problem, is to hard wire the machine to the network. Wifi is enabled later in the startup sequence which leaves little (or no) time for the update to get picked up an applied before the boot crashes. The wired network stack starts up much earlier in the cycle and will maximize the odds of the fix getting applied in time.
That makes sense with how the article said “up to 15 times” which does sort of indicate it’s not a counter or strictly controllable process. Thank you!
I was thinking (from reading the headline) that if one specific component fails 15 times during boot or so, it will just automatically get disabled by the system, so that you don’t run into an unavoidable boot loop.
But this makes sense as well, if they did write “up to” in the article (as others have stated).
Even though I find the confidence weird. Imagine you have some weird dial-up or satellite internet solution for your system, which just needs time to connect, and then maybe also just provide a few bytes/kilobytes per second. This must be rare, but I’m 100% confident that there exists a system like this :DEdit: okay, I should read first. The 15 times thing is said for azure machines.
macOS has something to this effect where if it detects too many kernel panics in a row on boot it will disable all kernel extensions on the next reboot and it pops up a message explaining this. I’ve had this happen to me when my GPU was slowly dying. It eventually did bite the dust on me, but it did let me get into the system a few times to get what I needed before it was kaput.
Interesting to know :)
I am so confused. What’s supposed to happen on the 15th reboot?
The IT guy quits and it’s no longer their problem to fix
Probably triggers some auto-rollback mechanism I’d guess, to help escape boot loops? I’m just speculating.
Welp, Ars Technica has another theory:
Microsoft’s Azure status page outlines several fixes. The first and easiest is simply to try to reboot affected machines over and over, which gives affected machines multiple chances to try to grab CrowdStrike’s non-broken update before the bad driver can cause the BSOD. Microsoft says that some of its customers have had to reboot their systems as many as 15 times to pull down the update.
Yep. That makes more sense. Thanks!
That’s some high quality speculation
Just imagine if it’s a build farm with hundreds of machines. Jesus. That’s a hell I wouldn’t even wish on my worst enemy.
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Have you tried turning it off and back on again?
Hey I missed one of your messages because I was rebooting. What did it say?
Hey I rebooted 14 times now, just as you told me, but it’s still not working.*
:D
No no.
Have you tried turning it off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on and off and on again?
God damn it i’ve been rebooting it 15 times Gay. 🤦♀️
that was your first problem. if it was designed by techbros, always assume it’s Straight.
Yep, that’s definitely a fix…
It sounds exactly like a Microsoft fix.
Well in the time until Windows rebooted 15 times Windows 12 will be out.
the 12 is for how many times you need to reboot it when you first get it
We did get 7 computers back by 1am last night just by constantly rebooting.
That said, 40 out of 47 never came back. So clearly something more is needed.
Have you tried 15 more reboots?
there’s an easy fix. it could be done with a single boot attempt if M$ hadnt made it so needlessly difficult to enter safe mode
Many of the machines in question will have safe mode walled off for security reasons anyway.
fair enough. i can see that disabling safe mode would be a decent security measure. but by the time that kind of exploit is used, you’ve already got bad actors inside your network and there are much easier methods available to pivot to other devices and accounts.
Laptops are often taken outside the network.
Well then obviously you could opt to restrict safe mode on laptops only, or laptops and desktops allowing you to get your server infrastructure up quickly so at least the back end is running properly.
Ffs.
Servers with KVM access, could have it compromised, letting bad actors enter safe mode.
If your RMM gets compromised then you have much larger issues.
Doesn’t need to be fully compromised, but it isn’t unusual for the access credentials to some portion, to be stored on an easier to compromise system. Disabling safe mode on a server, prevents stuff like a single compromised laptop, from becoming a full server compromise.
Most of our machines at my office run Win 10 or 11 and we haven’t had the blue screen. I was wondering why we hadn’t experienced this. Still don’t know.
Azure is MS’s cloud computing. As long as you weren’t using MS OneDrive, or 365 Office, or something else that relied on MS cloud, you’re good.
Actually it’s due to whether your company uses CrowdStrike or not.
Supposedly, one of the fixes (aside from rebooting and hoping it grabs the update fire) is to delete a single file in the CrowdStrike directory after booting into safe mode.
I just spent the morning doing this with my help desk team, although we just do it via command prompt at the recovery screen. We’ve had a 100% success rate so far at 93 devices and counting. I’m glad our organization practices read only Friday, at least.
Tbh, I would then also not update anything on Thursdays (which does maybe do overnight procedures) since it may be breaking over night then, leaving you just little time to fix before the weekend :D
This kinda can be extended up until Monday, I know, but, at least in Germany, on Fridays people go home way sooner than other days.
Yes, but Azure platform itself was using it. So many of those systems were down overnight (and there’s probably still stragglers). The guy you responded to specifically called out Azure-based services.
Sure, but the OP of the thread didn’t.
Most of our machines at my office run Win 10 or 11 and we haven’t had the blue screen. I was wondering why we hadn’t experienced this. Still don’t know.
So it isn’t whether you’re using Azure, it’s whether you’re using CrowdStrike (Azure related or not)
So it isn’t whether you’re using Azure, it’s whether you’re using CrowdStrike (Azure related or not)
No. Azure platform is using Crowdstrike on their hypervisors. So simply using Azure could be sufficient to hurt you in this case even if your Azure host isn’t using Crowdstrike itself. But yes, otherwise it’s a mix of Windows+Crowdstrike.
Can you source your claim, that Azure hypervisor uses CrowdStrike? Because a Microsoft spokesperson told Ars that that issue was unrelated to the CrowdStrike update.
[…] cited as “a backend cluster management workflow [that] deployed a configuration change causing backend access to be blocked between a subset of Azure Storage clusters and compute resources in the Central US region.”
A spokesperson for Microsoft told Ars in a statement Friday that the CrowdStrike update was not related to its July 18 Azure outage. “That issue has fully recovered,” the statement read.
Microsoft services were, in a seemingly terrible coincidence, also down overnight Thursday into Friday. […]
A spokesperson for Microsoft told Ars in a statement Friday that the CrowdStrike update was not related to its July 18 Azure outage. “That issue has fully recovered,” the statement read.
They were not “using it”. And there’s no “stragglers still”.
You don’t use CrowdStrike presumably
Why bother encrypting passwords? Just store them in plaintext, preferably on a web server that’s publicly accessible so other services can easily access them.
Excel sheets… I prefer them in tables, rather than plain text. I’m kind of a sysadmin… You know…
This is what we based our KBA on to get our users back into Windows:
https://x.com/timshadyeth/status/1814210120613847118?t=DsfwJAnEyqGInjLWHpvM2w&s=19