
- Hand washing (dishes or clothes) is inherently extremely inefficient compared to machine washing. It wastes a lot more water and energy. Plus, machines clean better than hands in most cases. I hope you are joking and not actually considering a hand-washing robot to be an improvement over machine washers.
- The drier replacement is fine.
- The vacuum replacement is mostly fine, but a regular vacuum with a robot arm to move stuff would be better
- Why do you want to spend less time with your pet? Feed them yourself
- Using a robot to open a door is just plain stupid. Why would you ever want to wait for a robot to drop what it’s doing, walk to the door, open it, and go back to its task… When an automatic lock costs next to nothing and is instantaneous
- Toaster… Would the robot… Like… Heat its hands while holding the bread?
- Fan… Do you want it flap its hands to make wind?
- Large fridge… Some people have never played “professor Layton” and it shows
- Coffee maker… Fine… Whatever…
- Double entry
- Double entry
- The litter box cleaning is also fine
- 10 Posts
- 110 Comments
Joined 3 years ago
Cake day: February 1st, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 2·16 days ago
2·16 days agoYou don’t. That’s why it must be reputable sources
Ah, sorry, I misinterpreted you. DM is fine. I have never used Lemmy’s DM, I expect it to be bad. I have put a matrix address on my Lemmy profile. It’s probably better than Lemmy’s DM
I see, I’m not sure I can help you with that. I don’t really engage with many communities outside of Lemmy. I just lurk in various other places.
Anyway, it looks to me like you are looking for an online bubble where to efficiently isolate yourself, this can’t be good for you. I would suggest meeting with real people instead. Are you still a student? Maybe in university? Then you are probably surrounded by people your age with common interests to you, waiting for you to speak to them. Make friends, it will be fun.
That being said, I do share some of your social anxiety, so this is definitely a “do as I say, not as I do” kind of situation.
Interesting, I didn’t know you could do that through the portal directly.
I was only familiar with uinput because I have used it before to use a wiimote as a mouse, and for that you’d actually want to emulate a mouse.
Btw, I just remembered.
You said that “if you could go to the store, buy a disc with the game, like in the good old days” you would prefer that over piracy.
I do encourage you to buy games on GoG (Good Old Games), download the installer, and burn it on a blue ray disk for you to keep.
For steam I already told in the previous comment, cs.rin.ru. You need an account to access the clean files threads.
For gog unfortunately not anymore. Check the r/piracy megathread, see if you find something
I forgot about the gog part. Yeah, you can also use those. There used to be a website that uploaded clean gog installers, but now all the download links are behind those sketchy filesharing services. Though, if you manage to get one, the binary should be signed by the developer. On windows I know you can check the signature by right-clicking on the file, on Linux I don’t remember because I haven’t needed it in a long time.
For the VM you need qemu/kvm. I suggest to use virt-manager which is just a graphical interface for qemu.
First of all, don’t expose yourself to danger. Get your pirated games from reputable sources.
Most games only need a Steam emulator like Goldberg’s to run without license, and you can get clean steam files from cs.rin.ru. You don’t need VMs for this, it’s literally the original game.
If you need an actual crack, you can also look up on cs.rin.ru and try to gauge the reputation of the uploader. You can also check fitgirl or dodirepacks, they are both highly reliable. These are unlikely to have malware, but it’s not impossible.
If you want to use a vm because you still don’t trust the pirated game in question (reasonable), then there is no shortcut. Use the arch wiki to learn how to setup a VM with GPU passthrough, even if you don’t use arch it’s always a good place to get started.
The proper way to programmatically move a cursor on Linux is using
uinput.Anything you were doing that worked in xorg and not in wayland was more akin to a weird remnant from the 80s than to an actual solution.
However, there will likely be full featured applications that already do whatever you were trying to do.
- they both suck in different areas and excell in others
- Vim is only useful when SSH-ing into an embedded device. Emacs can’t even do that. So I agree…
- Tautology
- Tautology
- Yes, but you still need C in a handful of situations
Adding:
- All Unix style shells suck, and the shell should not be based on human readable text, but on serializable objects like in powershell
- The kernel should support windows style acls
But if it had that issue, you could have solved it by mounting gtk settings info the flatpak
Some apps Will draw their own cursor and there’s nothing you can do about it. However, what’s happening here might be something else, so, are these apps in flatpak?
Can you install different OSes. Or are you limited to the vendor provided build of osmc?
Don’t use a raspberry pi.
RPI5 only has h265 decoding, everithing else is handled by the cpu. Which is fine for 1080 as long as that’s all the sbc is doing, but if you are also running some server, or you want anything h264 above 1080 you are out of luck.
RPI4 should be a little better, it has h264 and h265, don’t know the supported resolutions/framerates, but the cpu is considerably less powerful. Also, the cpu lacks encryption acceleration, so if your are getting your movies over https that’s gonna take a toll.
Older Pis are goint to be unsupported by kodi and jellyfin, so don’t get those.
None of these is a dead no-go, listen to other peoples experiences. But I personally would advise against any Raspberry Pi. Maybe and Orange Pi is better? I don’t know. My suggestion is to avoid the SBC, and get a cheap second hand Intel pc instead (possibly a very low power one). Intel’s quicksynk video accelerator is gonna run laps around any sbc at any resolution, and it’s gonna support more decoders, and even some encoders if you want to run transcoding in a jellyfin server.
Edit: If intel sold a quicksink pcie card, I would put one in my rpi5. But it don’t.
Edit 2: I should add that some streaming services block 4k on Linux
If it’s a Wayland application it will support global shortcuts.
For X11 apps. If you are on KDE there’s this menu:
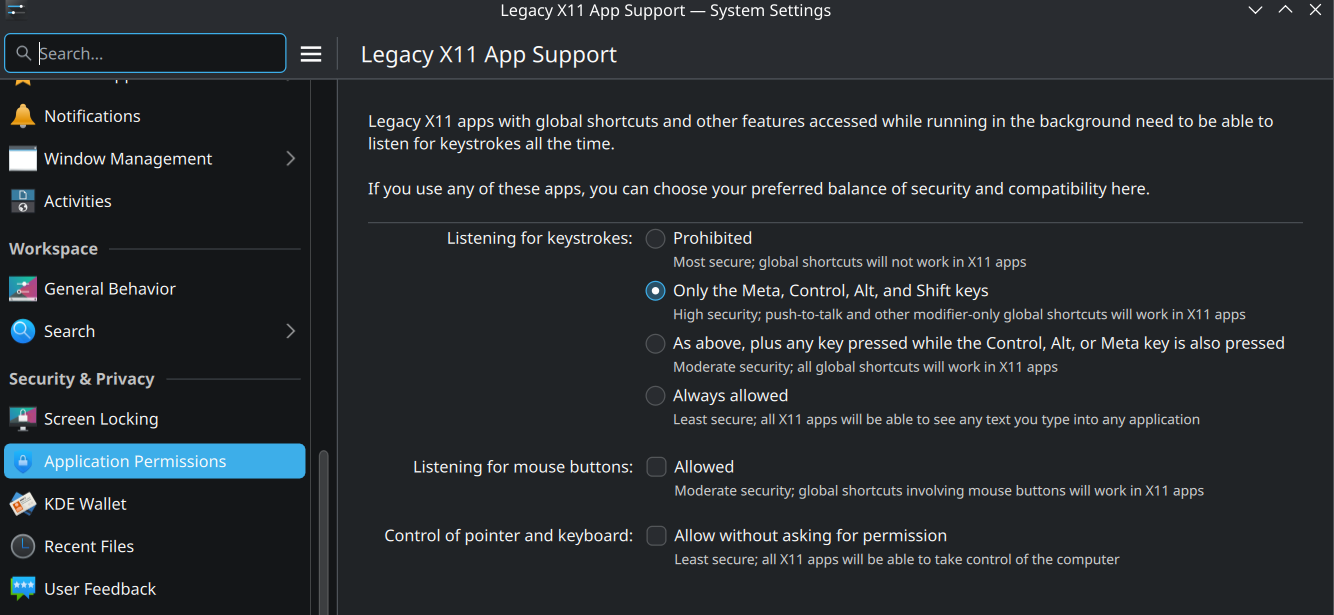
Other DEs have different ways to deal with this.
And if you are on Gnome, change DE. Gnome will always follow its own philosophy, because apparently it doesn’t align with yours, you should use something else.
Btw, I gave the same answer in the previous comment.
Also, on the “how can you consider this polished”… Wayland supports global shortcuts, this is a fact. What it doesn’t support is “global shortcuts for apps that use a protocol that is not Wayland”. I think I made my point
https://github.com/X11Libre/xserver/pull/56
Here is the x11libre dev not understanding what the
^operand does in C. Would you trust running this person’s code as a display server?Sure. No one expects anyone to know everything from the start, and people improve with time. But this was metux’s understanding of C when he forked off xorg thinking he could do better than freedesktop.
That is a feature. Allowing arbitrary programs to read any key press is how you get keyloggers.
Wayland has a protocol to request reading keys out of focus (which will ask the user for permission, as opposed to just read it like on xorg).
If the program was running in xwayland (which it probably was) of course it won’t use that protocol, and will just try to read it X11 style.
In some DEs (KDE) you can select if X11 apps are allowed to read keys.
“I switched to X11 and it immediately works”. I’ll give you another tip: if you run
chmod 777 -R /the file manager stops pestering about permissions and it immediately works.
Test better.
- Discord works
- Teams works
- OBS works
- Sunshine works like a charm
- Built-in VNC/RDP servers work
- I think zoom also works
Of course you can expect things with names like “Xultra-Xold-Xscreen-Xsharing-Xtool-11” to not work. Trying any of those and complaining it doesn’t work is just disingenuous and facetious.
Edit: I forgot you had a real question after the misinformation. Here’s some things Wayland does better
- It supports HDR
- It doesn’t tear
- It’s by design more efficient
- It’s more secure
- It actually support track pads with kinetic scrolling (if you think kinetic scrolling works on X11 it means you don’t know how it works)
- To crash the screensaver you need to crash the whole desktop, which means you don’t get unauthorized access to it
- It actually supports multiple monitor (with different resolutions, different scales and different refresh rates)
- They just merged actual support for multiple GPUs (xorg doesn’t have that)
- It supports explicit sync (xorg supports just enough to run inside Wayland)
- It’s supported by Nvidia GPUs (for X11 you need to use Nvidia’s closed source bespoke implementation of xorg)
But it’s just to name a few, you know…



{kind=link}
Washing: I’ll concede that one. But I’m not completely sold.
Door: a lot of newly made vehicles already have automatic doors that unlock when you get close. You can already build an automatic lock if you want to, it’s not even that expensive.
Vacuum: having a big ass humanoid robot walk around with a vacuum is ridiculous when you can just put wheels on the vacuum and let it walk itself around. The humanoid robot can move stuff, it’s true, but you can just put an arm on the robot vacuum.
Toaster: dude, you just complained about the energy efficiency of a washing machine, and now you want to toast bread on a stove? That’s ridiculous, just give it up.
Fan: I’m starting to think you just want the “thrill” of owning a slave
Fridge: Professor Layton is a game about a professor that solves mysteries and puzzles. Try it, it’s fun. 90% of people who played it as a child have shown improved mathematical and logical thinking, and packing skills (it’s not true, I made it up).
Wake on Lan already works. You just don’t know how to configure dnat.