

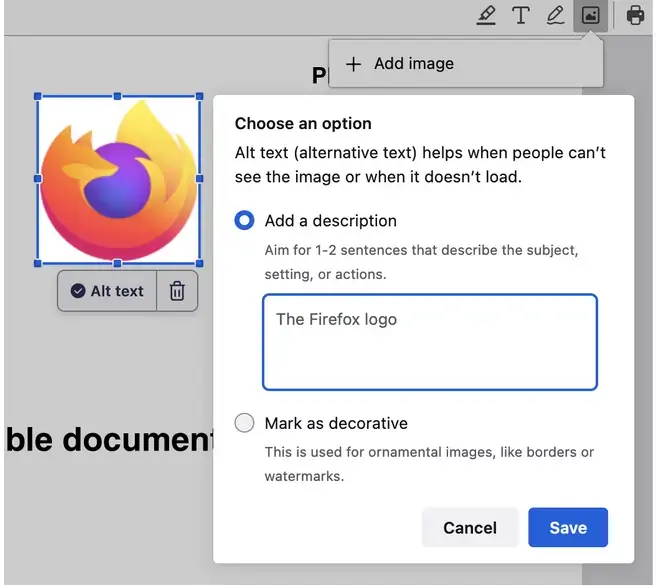
New accessibility feature coming to Firefox, an “AI powered” alt-text generator.
"Starting in Firefox 130, we will automatically generate an alt text and let the user validate it. So every time an image is added, we get an array of pixels we pass to the ML engine and a few seconds after, we get a string corresponding to a description of this image (see the code).
…
Our alt text generator is far from perfect, but we want to take an iterative approach and improve it in the open.
…
We are currently working on improving the image-to-text datasets and model with what we’ve described in this blog post…"
Overall see nothing wrong with this. Encourages users to support alt-text more, which we should be doing for our disabled friends anyway. I really like the confirmation before applying.
On the one hand, having an AI generated alt-text on the client side would be much better than not having any alt-text at all. On the other hand, the pessemist in me thinks that if it becomes widely available, website makers will feel less of a need to add proper alt-text to their content.
A more optimistic way of looking at it is that this tool makes people more interested in alt-text in general, meaning more tools are developed to make use of it, meaning more web devs bother with it in the first place (either using this tool or manually)
If they feel less need to add proper alt-text because peoples’ browsers are doing a better job anyway, I don’t see why that’s a problem. The end result is better alt text.
I don’t think they’re likely to do a better job than humans any time soon. We can hope that it won’t be extremely misleading too often.
I don’t think they’re likely to do a better job than humans any time soon.
Sure, assuming the human is actually putting effort into the task. But we know that able-bodied society is generally, at best, dismissive of the needs of the disabled and, at worst, discriminatory. I very much doubt that the majority of fully sighted humans working in this area are taking the time required to view the problem from the point of view of the visually-impaired minority and then putting in the effort required to deliver the best possible solution for them. Not every website is run by some massive company with employees specifically dedicated to this task. For many it will be an afterthought, and that’s where AI descriptions will shit all over the lazy human ones. Additionally, alt text contributes to SEO which means many will be tailoring it to their search ranking instead of the needs of the user.
I dunno, I suspect most human alt texts to be vague and non descriptive. I’m sure a human trying their hardest could out write an AI alt text… But I’d be pretty shocked if AI’s weren’t already better than the average alt text.
Alt text: It’s for SEO, isn’t it?
- Marketing
True, but if it genuinely works really well then does it really matter? Seems like the change would be a net positive.
Babe another pointless Al just dropped
it’s not pointless; it’s amazing for accessibility, especially in pdfs.
Well I do agree it’ll be useful for people who need it, but for most people it’s pretty pointless and I hope at least they don’t enable it by default just like Windoze sticky key because ai use a lot of system resources for a little benefits especially with self hosted ai
beehaw is a safe-space, we shouldnt villify the experiences/needs of people who need alt-text. this could be game changing for people who need it.
Alternatively, it could be very frustrating for people who need it. Computer-generated translations are often very bad compared to human ones, and image recognition adds another layer of complexity that will very likely lack nuance. It could create a false sense of accessibility with bad alt-text, and could make it more difficult to spot real alt-text if it isn’t being tagged or labeled as AI generated
i don’t think we disagree in a vacuum but bringing that up in the context of this particular thread is probably unhelpful
“I don’t need Alt text so it must be useless”
This is actually one of the few cases where it makes sense. Its for alt-text for people who browse with TTS
Yeah, this is actually a pretty great application for AI. It’s local, privacy-preserving and genuinely useful for an underserved demographic.
One of the most wholesome and actually useful applications for LLMs/CLIP that I’ve seen.
Its for blind people, it let’s them know what is in images using a screen reader, just because it doesn’t apply to you doesn’t mean it’s useless
Think AI is pointless when it doesn’t apply to you?
If you had a visual disability you would certainly think otherwise.
Tell me you don’t add alt text to your posts without telling me :p
This seems like a very useful feature, and a great benefit to blind web users
From your OP description:
EDIT: the AI creates an initial description, which then receives crowdsourced additional context per-image to improve generated output. look for the “Example Output” heading in the article.
That’s wrong. There is nothing crowd sourced. What you read in the article is that when you add an image in the PDF editor it can generate an alt text for the image, and you as a user validate and confirm it. That’s still local PDF editing though.
The caching part is about the model dataset, which is static.
my bad, i misunderstood. thanks.
When I used a similar feature in Ice Cubes (Mastodon app) it generated very detailed but ultimately useless text because it does not understand the point of the image and focuses on things that don’t matter. Could be better here but I doubt it. I prefer writing my own alt text but it’s better than nothing.
Neat. I just hope it can be disabled to save power.
Power management is going to be a huge emerging issue with the deployment of transformer model inference to the edge.
I foresee some backpedaling from this idea that “one model can do everything”. LLMs have their place, but sometimes a good old LSTM or CNN is a better choice.
One thing I’d love to see in Firefox is a way to offload the translation engine to my local ollama server. This way I can get much better translations but still have everything private.
Now i want this standalone in a commandline binary, take an image and give me a single phrase description (gut feeling says this already exists but depending on Teh Cloudz and OpenAI, not fully local on-device for non-GPU-powered computers)
Ollama + llava-llama3
You now just need a cli wrapper interact with the ollama api
So, it’s possible to build but no one has made it yet? Because i have negative interest in messing with that kinda tech, and would rather just “apt-get install whatever-image-describing-gizmo” so i wouldn’t be the one who does it
this is how i feel about basically all technology nowadays, it’s all so artificially limited by capitalism.
nothing fucking progresses unless someone figures out a way to monetize it or an autistic furry decides to revolutionize things in a weekend because they were bored and inventing god was almost stimulating enough
Folks have made it - I think ollama was name-checked specifically because it’s on Github and in Homebrew and in some distros’ package repositories (it’s definitely in Arch’s). I think some folks (at least) aren’t talking about it because of the general hate-on folks have for LLMs these days.
I don’t want an LLM to chat with or whatever folks do with those things, i want a command i can just install, i call the binary on a terminal window with an image of some sort as a parameter, it returns a single phrase describing the image, on a typical office machine with no significant GPU and zero internet access.
Right now i cannot do this as far as i know. Pointing me at some LLM and “Go build yourself something with that” is the direct opposite of what i stated that i desire. So, it doesn’t currently seem to exist, that’s why i stated that i wished somebody ripped it off the Firefox source and made it a standalone command.
I thought that feature was built into it, but okay.
And you expect someone just do it for you? You alrady get the inferencing engine and the model for free mate.
Yes I was just writing that, I would love to see more integrations that can talk against ollama.
The biggest problem with AI alt text is that it lacks the ability to determine and add in context, which is particularly important in social media image descriptions. But people adding useless alt text isn’t exactly a new thing either. If people treat this as a starting place for adding an alt text description and not a “click it and I don’t have to think about it” solution I’m massively in support of it.
They just need to gamify it. Have a “Verified Accurate Alt-Text Submissions” leaderboard or something.
I would expect it’d be not too hard to expand the context fed into the AI from just the pixels to including adjacent text as well. Multimodal AIs can accept both kinds of input. Might as well start with the basics though.
So, planned experimentation and availabiltiy
- PDF editor when adding an image in Firefox 130
- PDF reading
- [hopefully] general web browsing
Sounds like a good plan.
Once quantized, these models can be under 200MB on disk, and run in a couple of seconds on a laptop – a big reduction compared to the gigabytes and resources an LLM requires.
While a reasonable size for Laptop and desktop, the couple of seconds time could still be a bit of a hindrance. Nevertheless, a significant unblock for blind/text users.
I wonder what it would mean for mobile. If it’s an optional accessibility feature, and with today’s smartphones storage space I think it can work well though.
Running inference locally with small models offers many advantages:
They list 5 positives about using local models. On a blog targeting developers, I would wish if not expect them to list the downsides and weighing of the two sides too. As it is, it’s promotional material, not honest, open, fully informing descriptions.
While they go into technical details about the architecture and technical implementation, I think the negatives are noteworthy, and the weighing could be insightful for readers.
So every time an image is added, we get an array of pixels we pass to the ML engine
An array of pixels doesn’t make sense to me. Images can have different widths, so linear data with varying sectioning content would be awful for training.I have to assume this was a technical simplification or unintended wording mistake for the article.I imagine it’s a 2D array? So width would be captured by uhh like
a[N].len.It could be I’m misunderstanding you, because not not sure what you mean by:
linear data with varying sectioning content
Looking at Wikipedia on arrays, I think I’m just not used to array as terminology for multi-dimensional data structures. TIL
Might be a significant issue if more applications adopt these kind of festures and can’t share the resources in a meaningful way.
I like this approach of having a model locally and running it locally. I’ve been using the firefox website translator and its great. Handy and it doesn’t send my data to google. That I know of, ha.
The only issue for Firefox’s translator currently is the time it takes to load at first, or the fact you have to download each model first. Its not some monumental task, but it does have more friction than Google’s “automatically send the site you are browsing to our server”
There are way more companies who want to text-mine user content than there are blind people using the internet to read my content.
But even for a simple static page there are certain types of information, like alternative text for images, that must be provided by the author to provide an understandable experience for people using assistive technology (as required by the spec)
I wonder if this includes websites that use
<figcaption>withaltemptied.MDN
figureandfigcaptionhas no mention of changed img alt intentions. Which makes sense to me.figure does not invalidate or change how img is to be used. The caption may often not but can differ from the image description. If alt describes the image, figcaption captions it.
What the fuck is Lemmy doing, breaking with HTML in code formatting?? Man it’s completely broken. I committed sth so it doesn’t remove the
imglol.<figure> img src="party.jpg" alt="people partying" /> <figcaption>Me and my mates</figcaption> </figure>Yes you can use both but I’ve seen some front end developers blank out
altaltogether when they are usingfigcaption.I did not find this practice in MDN Web Docs but I found it in an other place:
If you’re using an image that has a caption, it may not need alt text if the caption contains all of the relevant visual information.
I was just wondering what Mozilla’s method was for finding these images and if they took other things in to consideration like decorative images.
Interesting. It also made me look at the MDN docs again. img alt is consistent to that. I wasn’t aware of the empty for omittable images.
I also looked at
figureagain, and in my interpretation it does declare thatfigcaptionis to be used.figurerepresents self-contained content.figcaptionprovides the accessible name for the parent. The accessible name is is the text associated with an HTML element that provides users of assistive technology with a label for the element.The resolution order being aria-labelledby, aria-label, input[type=button][value], input[type=image]|img|area[alt], …
So
figcaptiontakes priority overimgalt.Thanks for the info. The Accessible name calculation page is really interesting.
Where is that quote from?
I put a link after the quote. That’s the source.
https://www.boia.org/blog/should-you-include-alt-text-for-pictures-with-captions
I think their might be something wrong with your browser or something. I tried the code blocks using spaces, tabs, and backticks, and I didn’t have the
imgproblem you had.I also checked from a different account on a different instance on a different browser this post and I can see the link.
Skimming through it it wasn’t fully clear to me, is this just for their pdf editor?
It is for websites. This is most useful for readers that don’t display images. The feature for websites should be added for version 130. I’m on Developer Edition and I am currently on 127. It will be implemented for PDFs in the future after that.
Thanks for clarifying
Where did you read this? The article says the opposite.
will be available as part of Firefox’s built-in PDF editor
Firefox is able to add an image in a PDF using our popular open source pdf.js library[…] Starting in Firefox 130, we will automatically generate an alt text and let the user validate it.
See also my other quotes in this comment.
will be available as part of Firefox’s built-in PDF editor
What you quoted is for the feature to add in images to PDFs. It doesn’t work for existing PDFs with images already.
In the future, we want to be able to provide an alt text for any existing image in PDFs, except images which just contain text (it’s usually the case for PDFs containing scanned books).
That’s how I read it atleaat. I could be wrong.
They’re starting this as an experiment in their PDF editor, yes. They then want to extend to PDF reading, and then hope to extend to the general web browsing.
will be available as part of Firefox’s built-in PDF editor
Firefox is able to add an image in a PDF using our popular open source pdf.js library[…] Starting in Firefox 130, we will automatically generate an alt text and let the user validate it. So every time an image is added, […]
In the future, we want to be able to provide an alt text for any existing image in PDFs, except images which just contain text (it’s usually the case for PDFs containing scanned books).
Once the alt text feature in PDF.js has matured and proven to work well, we hope to make the feature available in general browsing for users with screen readers.














{kind=link}
{kind=link}